主动模型治理
与数据研发工具无缝集成的智能助手,让模型治理更自动、更智能,提升模型研发效率 10 倍+
面临的挑战
- 中间层空心化严重,建模需求看不清理还乱。
- 应用层数据无序增长,时效、成本优化无从下手。
- 老模型汰换困难,新模型切不动、不敢切,价值收益无法量化。
实时在线的建模助手,10 倍提升模型研发效率
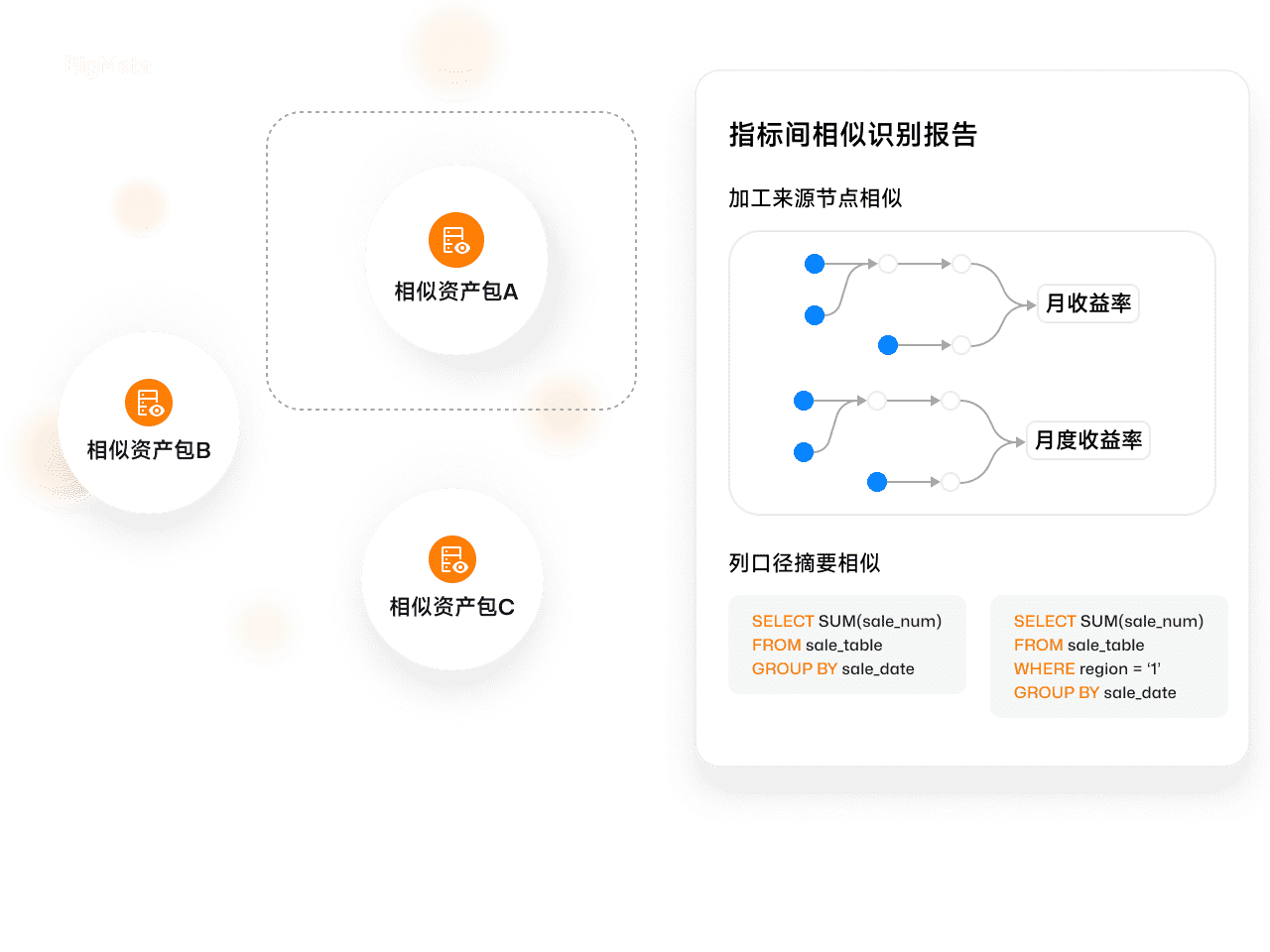
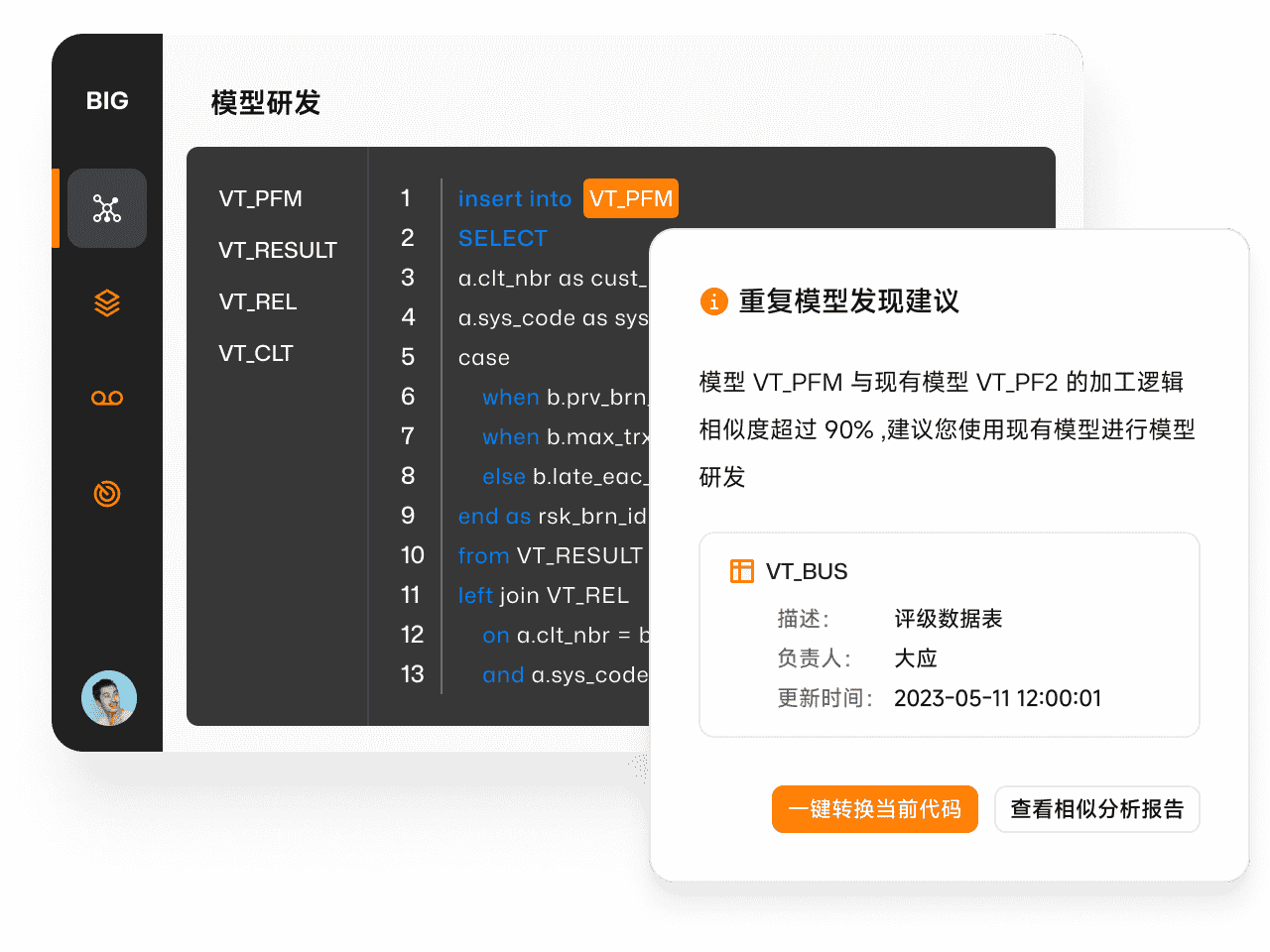
自动识别重复数据资产
内置高精度数据相似度评分算法,可自动扫描全域数据资产,精准识别重复计算、发现相似数据,并生成重复资产报告,基于可视化的字段口径及加工链路比对,可快速分析数据异同、有的放矢发起重复数据治理。
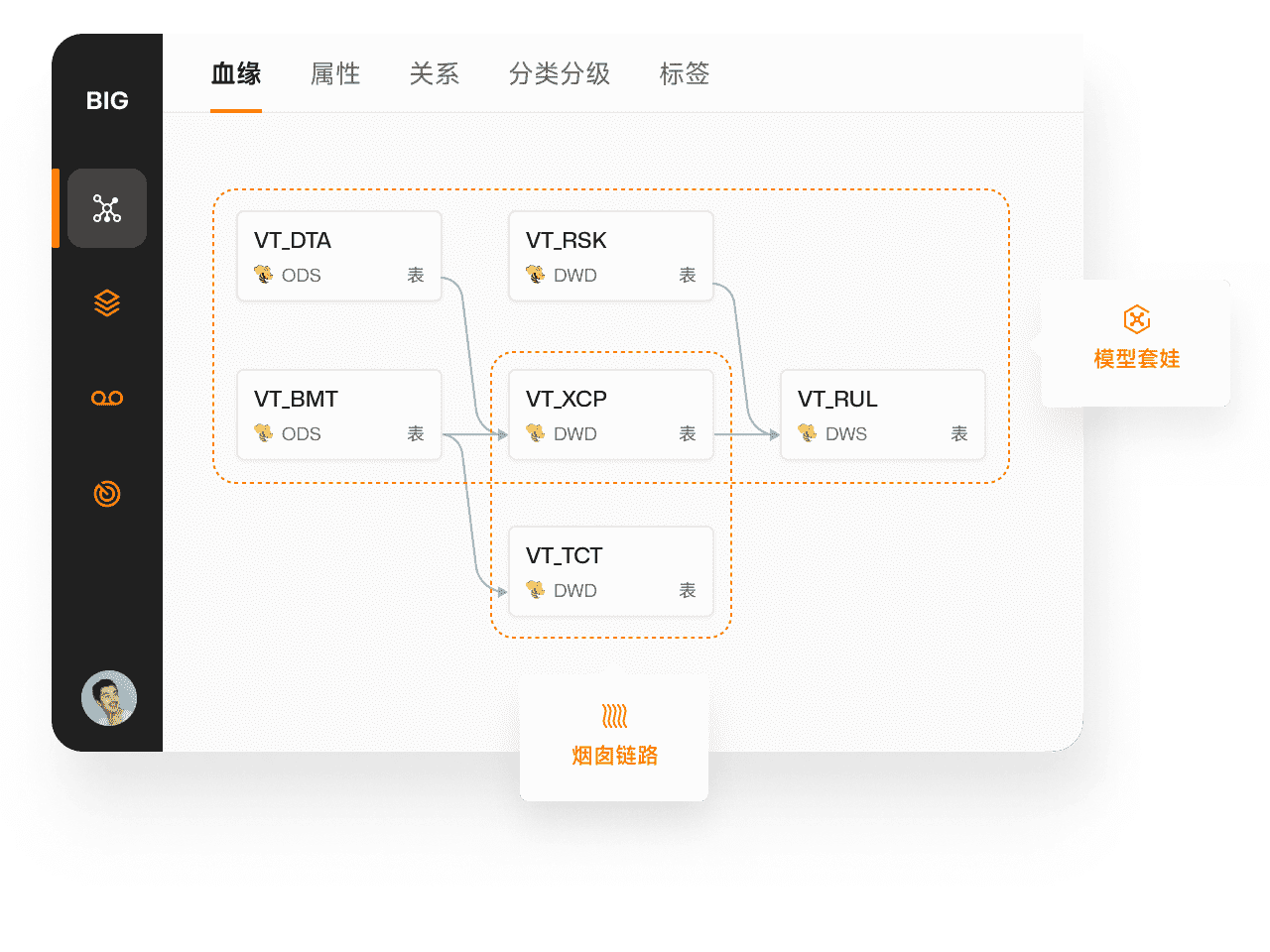
主动发现数据链路问题
内置高性能、高置信的数据链路问题识别算法,即使是 EB 级数据,亦可快速精准定位数据链路中存在的模型套娃、烟囱链路、低收益拷贝、不合理依赖等引发时效降低、成本激增、口径不一致等模型设计问题,持续为数据团队进行链路优化和模型重构提供高置信输入和建议。
模型研发智能代码建议
基于自定义数据管理策略,Aloudata BIG 可与数据研发工具无缝集成,在深度理解 SQL 算子语义的基础上,提供智能代码建议,如推荐用户引用更优的上游数据或避免重复建设相似数据或提示采用一致的方法操作数据等,让研发协作十倍提效。
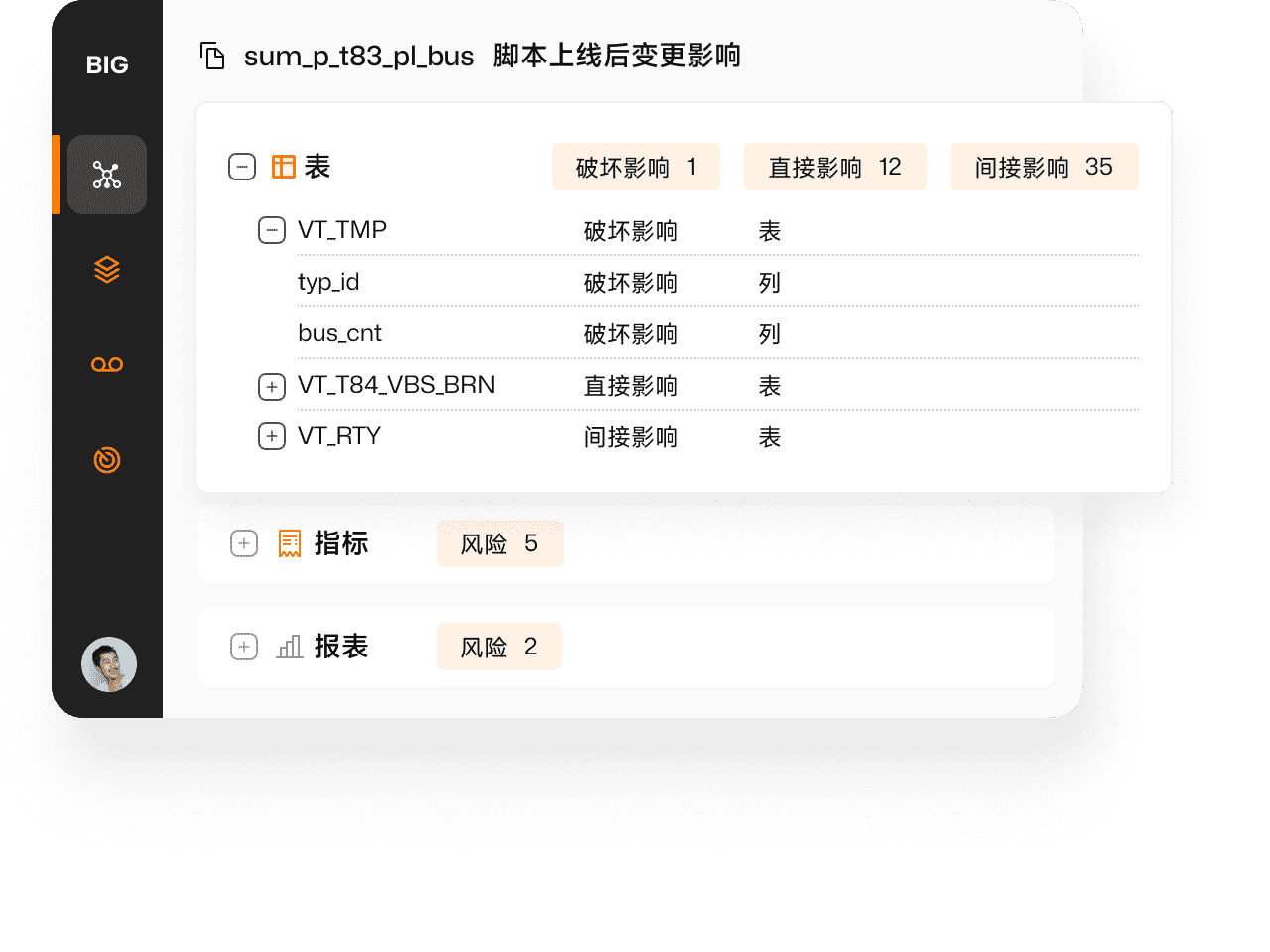
精准评估模型变更影响
算子级血缘极致精细地刻画了数据间的依赖,如字段间是直接沿袭还是间接影响、在何种条件下影响、影响明细值还是汇总值等等,进而针对模型变更对下游的影响进行细致到行列级的精准评估,从而避免表血缘快速扩散以致无法分析的窘境。
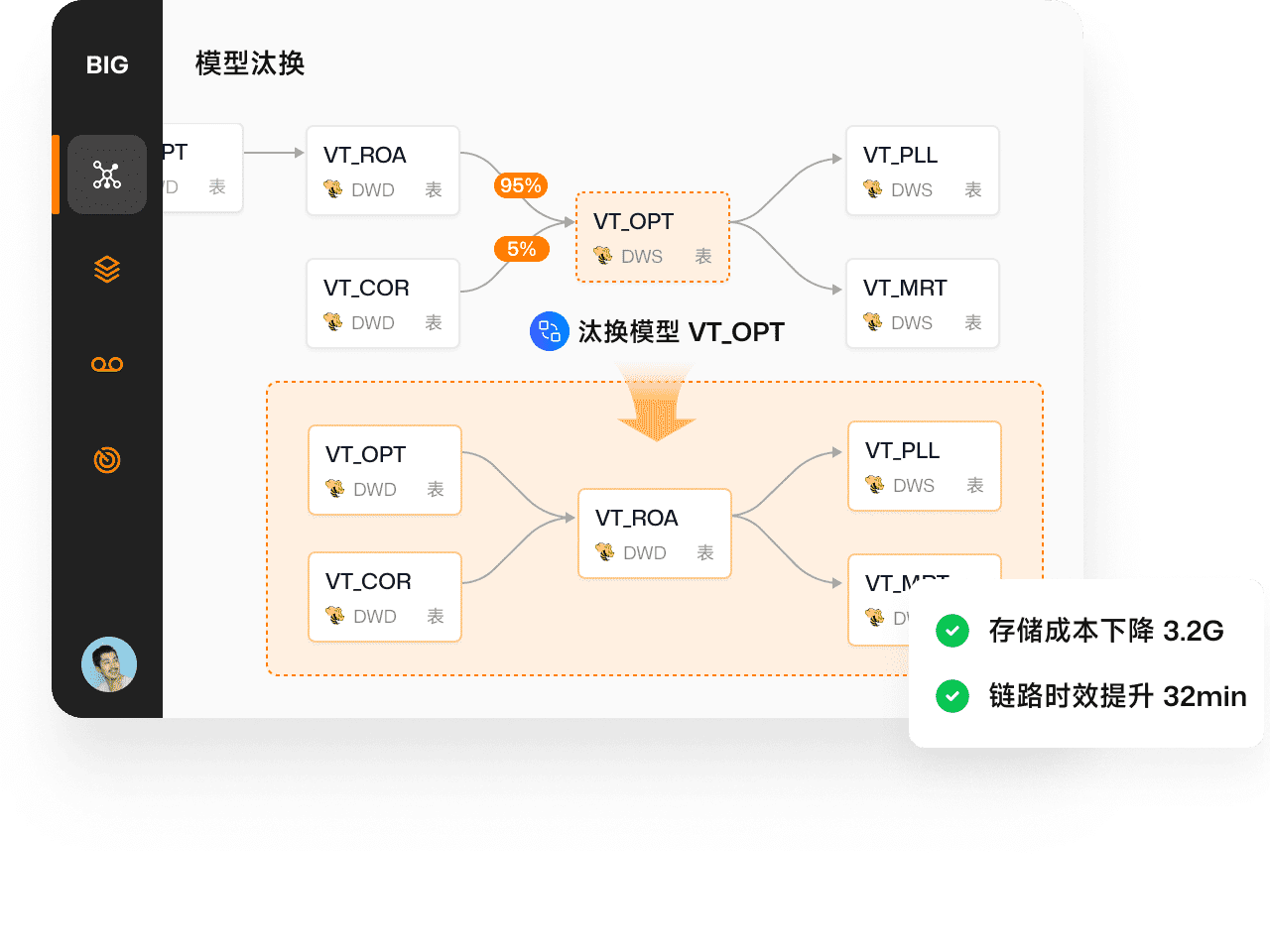
真实量化模型汰换收益
Aloudata BIG 可基于算子级血缘分析对比新老模型的加工链路差异,并通过代价模型预估计存成本和链路时效变化,以评估模型汰换收益,助力治理人员推动模型迁移切换,量化数据治理成果。
客户故事
相关解决方案

全域资产盘点
自动解析数据血缘,精准理解数据口径,高效盘点全域资产

敏捷运营决策
以指标为中心,搭建统一指标体系,运营决策提效 10 倍以上

全域数据管理
低成本沉淀全域数据资产,并提供统一的数据服务
客户故事

Aloudata x 招商银行:基于算子级血缘的变更协同和模型优化应用实践
招商银行以 Aloudata BIG 为基石,形成一套模型设计、数据开发和数据服务的长效管理机制,将现有血缘图谱升级为算子级血缘图谱,实现 99% 的血缘解析准确率,实现元数据应用智能化、链路保障自动化和架构治理长效化。推动数仓快速实现资产数量下降 40%、平均链路缩短 50%;在日常链路保障场景中,自动监测上游变更,自动评估精准到字段的端到端影响,帮助运维人员预防或快速定位数据风险,让上下游协同丝滑衔接。
相关解决方案
全域资产盘点
自动解析数据血缘,精准理解数据口径,高效盘点全域资产
敏捷运营决策
以指标为中心,搭建统一指标体系,运营决策提效 10 倍以上
全域数据管理
低成本沉淀全域数据资产,并提供统一的数据服务