为什么说逻辑数据编织是一种低门槛、高容错度、高 ROI 的数据集成与开发模式?
众所周知,数仓建模是一个技术含量很高的工作。
技术难度高的核心原因在于数据开发背后有着较高的隐性成本与潜在风险,技术水平的高下决定了业务需求的满足度,以及成本与风险的控制能力。
我们逐项拆解来说。
- 数据开发有哪些隐性成本与风险?
同应用开发不同,数据开发的对象不仅是代码,还伴随着数据的物理移动,开发工作流同数据流深度耦合。
数仓建模的产出物是分层的物理数据资产,资产的背后是一条条数据链路,包含着复杂的数据依赖关系和作业配置。因此,数据开发不仅要考虑业务逻辑与代码逻辑,还必须结合存储与计算引擎的类型和性能、数据量与增速、数据消费场景与频次、时效性要求等因素进行脚本的开发、调度作业配置与持续的作业监控与运维,确保数据可以按时、按质产出。
而数据又是动态的,数智化时代,业务系统和分析需求都面临着频繁的变化。在复杂的数据物理网络中,任何变更都意味着大量信息协同与人工运维工作。
随着企业数据量、用数人群和用数场景的增加,数据团队为满足业务需求会对数据进行预打宽和预汇总(打 Cube),来确保需求响应的效率,这种用空间换时间的操作无法确保所有的预计算结果都会被真正消费,进而产生了存算资源和运维投入的浪费;即便如此,需求的持续增加会导致数据团队难以兼顾模型的复用性和扩展性,集市层表数量快速膨胀、数据口径混乱、数据链路失控是数据仓库建设 3-5 年后的通病,数据治理的负担逐渐加大。
由此可见,数据开发的显性成本是存算资源的投入和开发人力投入,但隐性成本包含作业配置、监控运维、系统调优、变更协同、模型优化、数据治理等长期持续的人力投入,以及等待数据物理作业完成的时间成本。显性成本会随着需求线性增长,而隐性成本则是指数级增长。
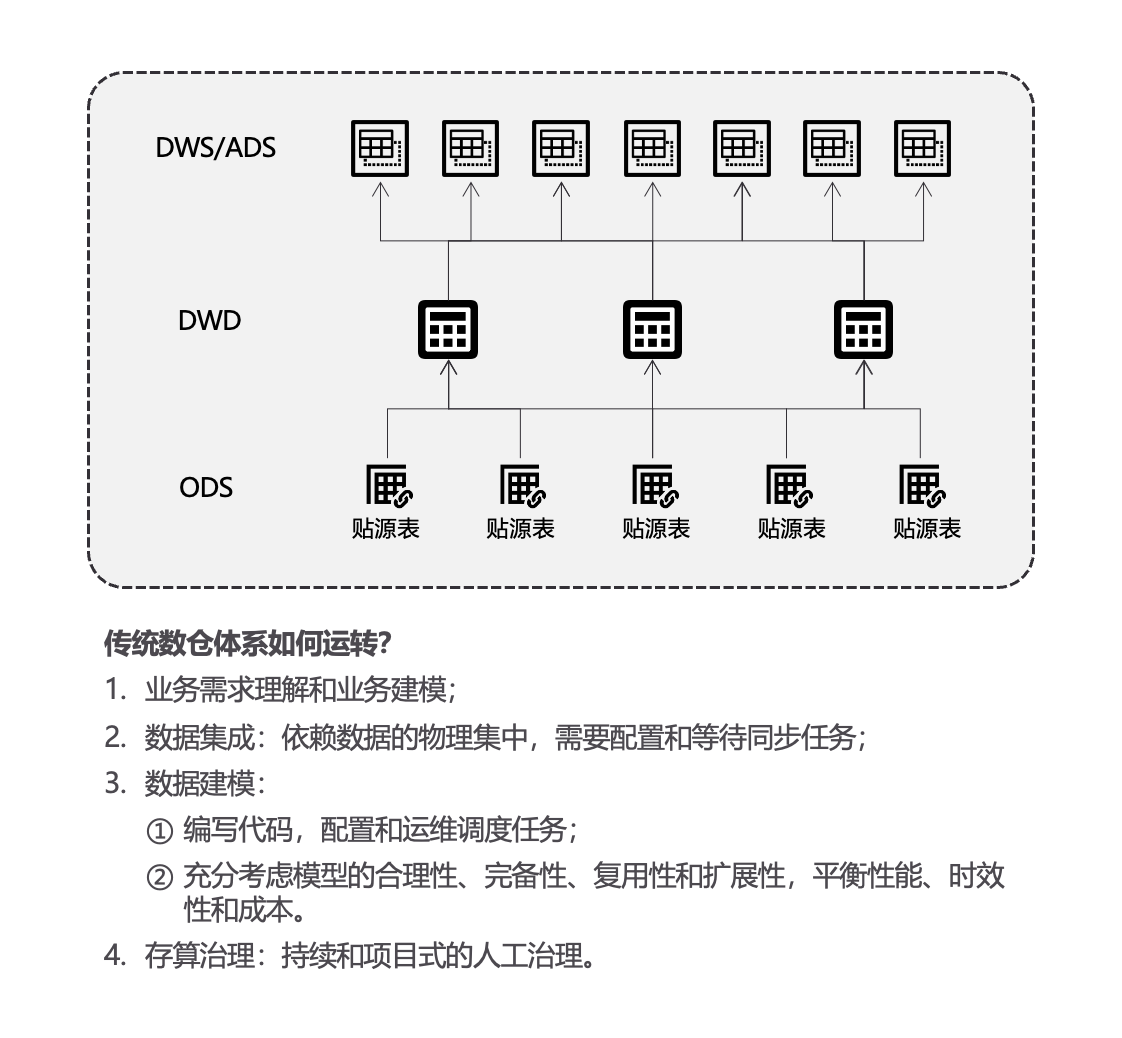
综上,数仓建模是一个技术含量极高的工作,因为模型质量直接影响了业务需求的响应效率,也直接决定了数据体系的成本投入。而数据链路的复杂性决定了模型一旦建成,很难任意调整,所以说,基于数据物理操作的数据开发,是一项高门槛、容错率低的工作,起步阶段就需要有很高的技术和投资门槛。
- 数仓建模水平高下体现在哪里?
从前文可以看出,数仓建模的本质是对业务需求的拆解、查询性能、数据产出时效性和成本的综合平衡,需要同时考虑业务逻辑、分析场景和目标、数据源情况(数据库类型、数据量、数据结构、更新节奏等)、基础设施条件等进行精心的分层模型设计。
从业务角度看,模型设计需要确保 ODS 层完整还原数据源的业务逻辑,DWD 层要准确抽象业务过程并确保数据模型能够提供充分的维度覆盖和明细信息,要充分考虑中间层资产的划分合理性、复用性、扩展性及完备性的需求,DWS 和 ADS 层则需要根据业务使用场景设计出合理的数据集市层,确保业务分析的时效性和便捷性。
从技术的角度看,要同时兼顾数据质量管理,数据产出的时效性,优化查询性能和响应时间,确保数据能够在合理时间里、高质量产出,确保下游消费端可以随时用上高质量数据资产。同时还要从数据安全和隐私保护,构建可扩展和高可用的数据架构以平衡业务响应效率、数据质量与存算成本。
总而言之,让业务(需求方)和 CFO(成本管理者)都尽量满意的数据工程师才是建模高手。然而,这种人才极度稀缺。
- 逻辑数据编织——初阶数字化企业的更优选择
回到本文的主题,我们向所有计划和正在建设数据体系的企业推荐一种全新的逻辑数据编织方案。
不同于物理数仓,逻辑数据编织平台不以数据的物理移动为前提,通过面向逻辑数据视图的操作实现数据的逻辑集成和抽象建模。这种模式将数据开发的工作流同物理的数据流进行了解耦,因此大幅提升了数据建模的效率、时效性和容错度。Aloudata 大应科技自主研发的 Aloudata AIR 逻辑数据编织平台便是国内数据编织领域的佼佼者。
接下来我们来具体分析下,逻辑数据编织如何实现低门槛、高容错度、高 ROI 的数据集成与开发。
使用 Aloudata AIR 进行数据集成、开发与查询的整体体验是这样的:
零搬运,秒级数据集成。通过地址和端口配置连接数据源(业务系统或数据湖仓),连接成功后即可通过统一的 SQL 语言对所有数据源进行查询和关联查询,无需配置同步任务和等待同步成功,即可实现数据的秒级集成。
NoETL,免运维。根据查询或建模需求进行逻辑数据视图的定义,定义方式同常规写 SQL 进行数据查询相同,支持复杂的视图嵌套。无需创建物理表、无需配置调度作业,系统自动拆解和路由查询请求到内置的流批引擎。因为逻辑视图的构建不伴随数据的移动,因此视图可以随时变更,变更立即生效。
自适应查询加速。在大数据量下,可以自动或手动生成与更新逻辑数据视图的关系投影(Predictive Relational Projection),系统自动将查询请求路由至关系投影或直接下推至源端查询引擎,实现查询加速。
自治理,物化视图智能回收。Aloudata AIR 依据查询行为自动回收低收益的关系投影或重新选择最佳投影构建方案,极大降低了存算治理负担。
通过上述流程可见,使用 Aloudata AIR 进行数据集成与开发大幅简化了数据工程的复杂性和工作量。工程师只需要面向业务语义(数据逻辑)进行逻辑视图的定义,而无需考虑数据的存放位置、数据源类型与各种源的特性与差异;不再需要通过手工作业调度配置、监控、运维和性能调优,系统会根据查询逻辑进行自动化的作业编排和智能的查询加速。
更重要的,数据的计算开销与物理移动是“以销定产”的模式:如同先进的“柔性制造”,产生订单再触发商品生产,再发起物流,逻辑数据编织则是不查询,无计算;不构建关系投影,无数据搬运。
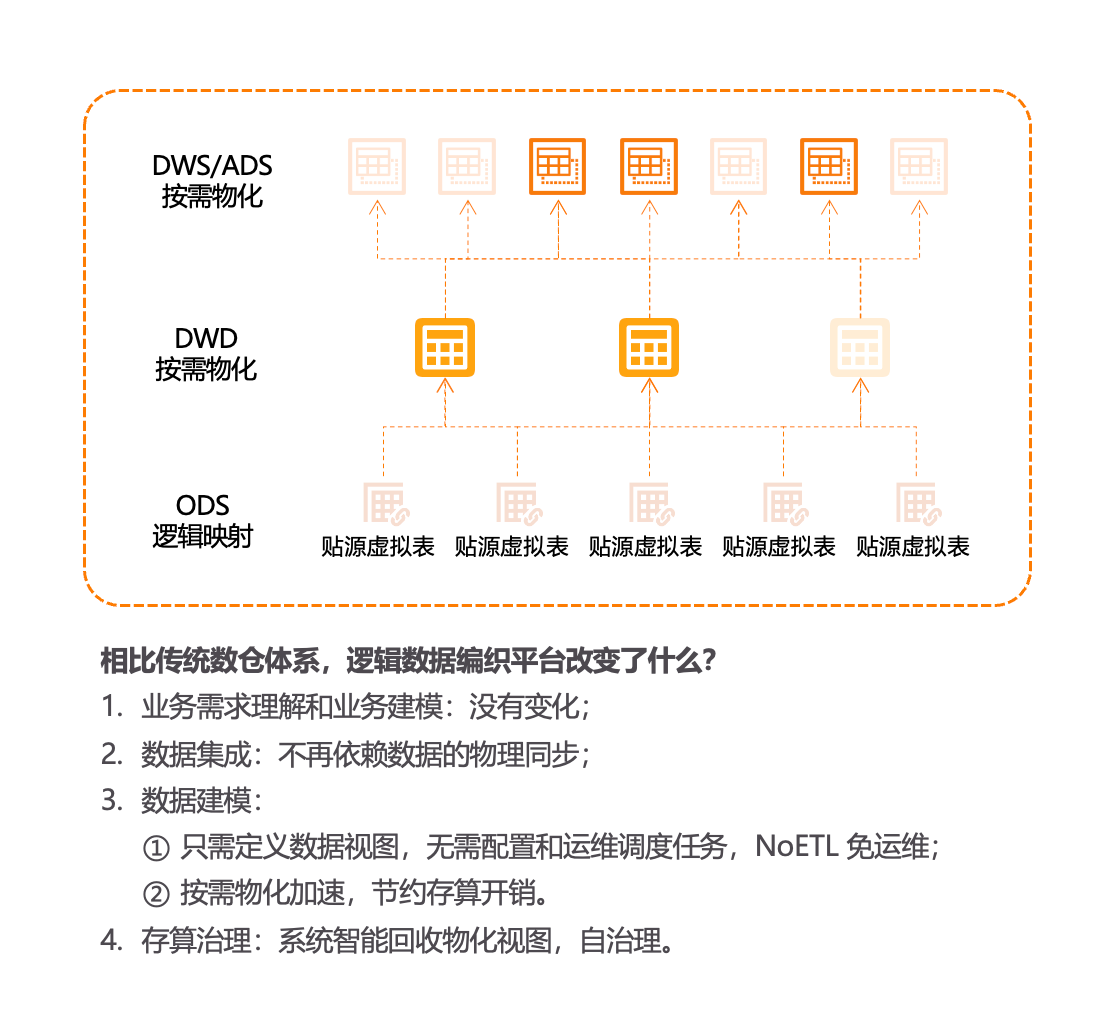
Aloudata AIR 逻辑数据编织平台让工程师在进行视图定义的时候,无需像传统数仓建模一样小心翼翼,慎之又慎:不必担心业务场景的覆盖度,因为开发周期大大缩短,可以通过按需开发代替过度建模;不必充分考虑模型的复用性和扩展性,逻辑数据视图的存算开销微乎其微,物化的关系投影也具有智能回收能力,即便出现冗余也不产生数据存算治理的负担;无需为数据的变更提心吊胆,逻辑数据视图变更即生效,关系投影可以随计算逻辑的变化自动完成数据更新。
曾经制约数仓建模效率的各种因素都不再存在,数据开发工作的技术门槛和初始投资显著下降,逻辑数据编织平台让数据工程师有了“先做起来,随时调整,快速迭代”的可能性。数据团队可以专注于业务需求的满足度,而非技术的复杂性、局限性和规范性,通过高效的数据交付效率与灵活的变更调整能力,同业务团队共同实现一个更高 ROI 的数据体系建设。


 微信公众号
微信公众号 浙公网安备 33010602011980 号
浙公网安备 33010602011980 号