产品发布|Aloudata BIG 全球首个实现算子级血缘解析的主动元数据平台
2021 年,Gartner 取消了发布多年的元数据管理魔力象限,取而代之的是主动元数据市场指南。Gartner 断言,数据管理的焦点已经从数据内容管理向元数据管理升级,而主动元数据是让数据管理更自动更智能的关键,这开启了业界对元数据管理发展趋势的新思考。
企业数据管理日益复杂化,尤其是对数字化程度较高的企业而言,业务用数已经成为常态,进而导致了数据更加分散——数据的生产和消费被分散到不同部门或分支机构建设,甚至存储在不同的数据源中,最终导致数据链路的复杂性日益增加,数据链路“看不清、管不住、治不动”矛盾越来越突出。
企业数据链路层次变得越来越难以管控,上游数据的变化很难被下游及时准确感知。通常情况下,只有在下游出现问题后,相关人员才会向上游追溯发现数据已发生变化或异常。
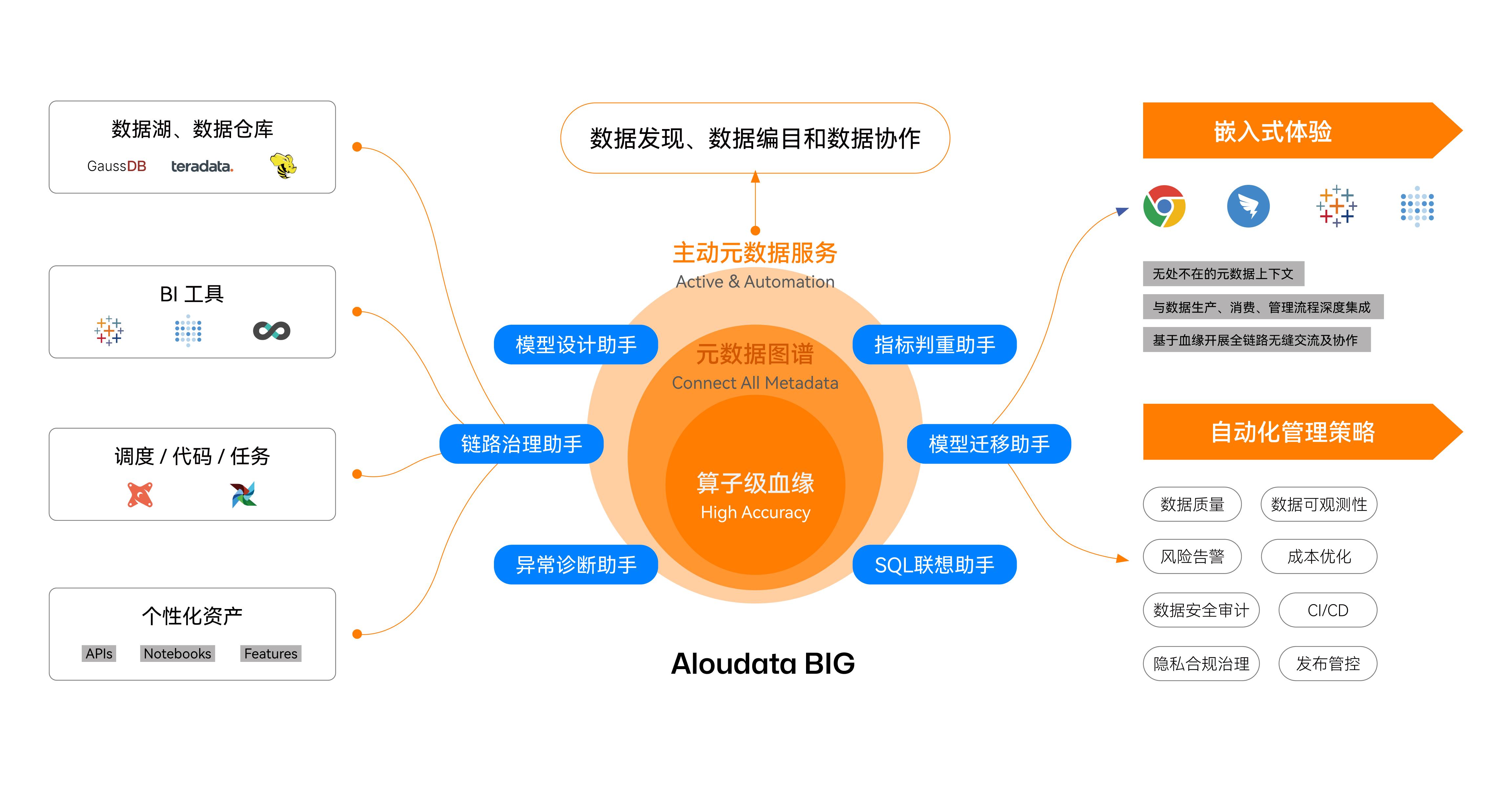
数据管理挑战十分明确且亟待解决,Aloudata BIG 作为全球首个实现算子级血缘解析的主动元数据平台,其研发目的正是通过技术手段达成数据管理自动化。
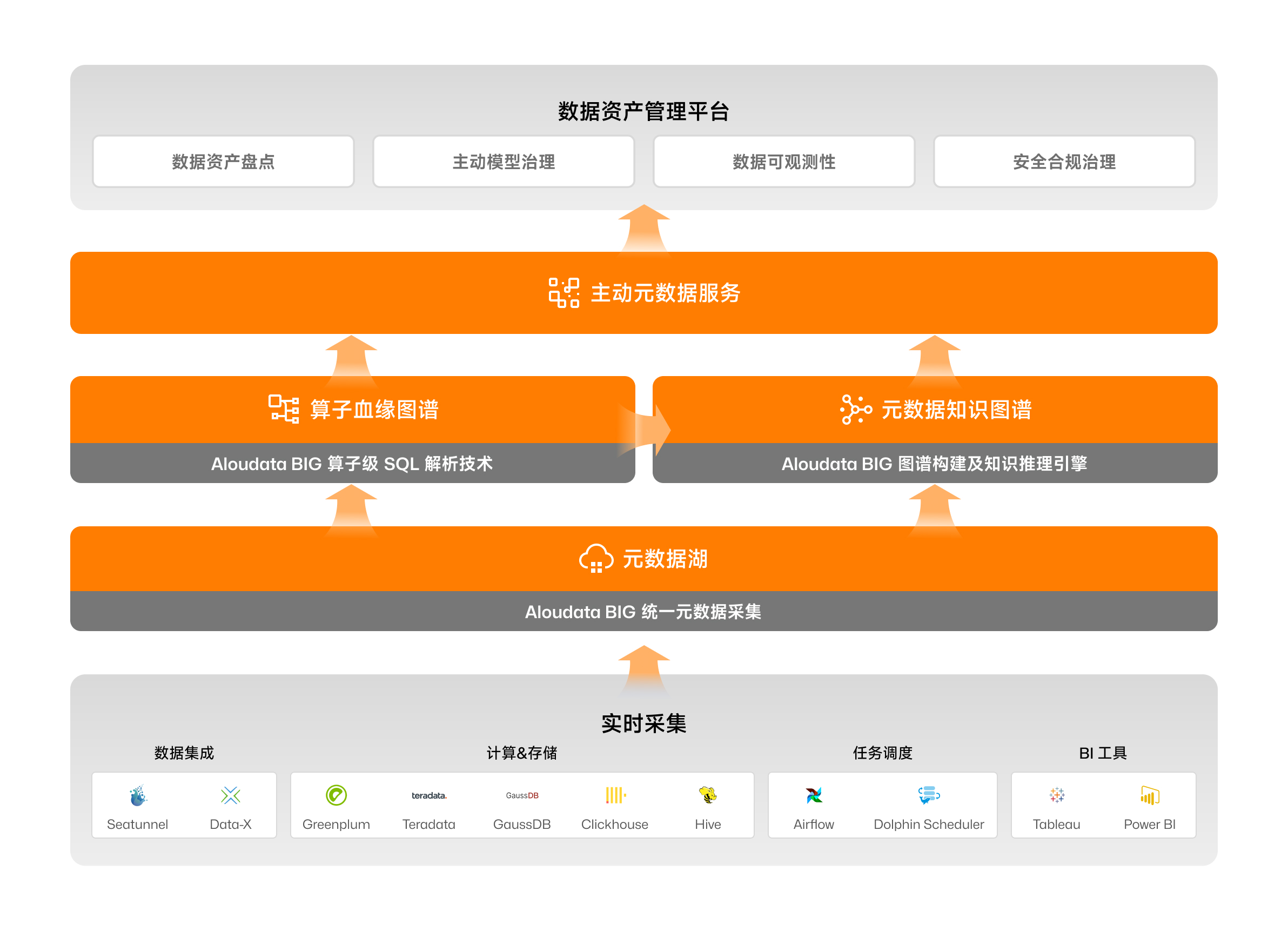
Aloudata BIG 主动元数据平台首先要解决的是企业数据管理的第一个主要难点——数据链路“看不清”的问题,当前数据血缘技术普遍存在不够全、不够准以及不够细的问题,由于无法精细、准确、全面地刻画数据链路,许多企业为了理清监管报送等重点链路的血缘以及各个字段的计算口径,只能耗费巨大人力进行人工盘点。Aloudata BIG在数据血缘解析技术上实现了重大突破,彻底根治了现有血缘技术的弊病。
Aloudata BIG 数据血缘的第一大特点是“精细”,可以实现对列算子级的高精度血缘解析,即便是最复杂的数据链路,也可轻松打开链路加工“黑盒”,抽取字段计算口径,清晰展示每一个字段的加工细节,而不仅仅是数据列间的依赖关系,数据人员可快速获知列与列之间是通过何种加工过滤或维度汇总得到的,而不需要费时费力去人工扒代码。
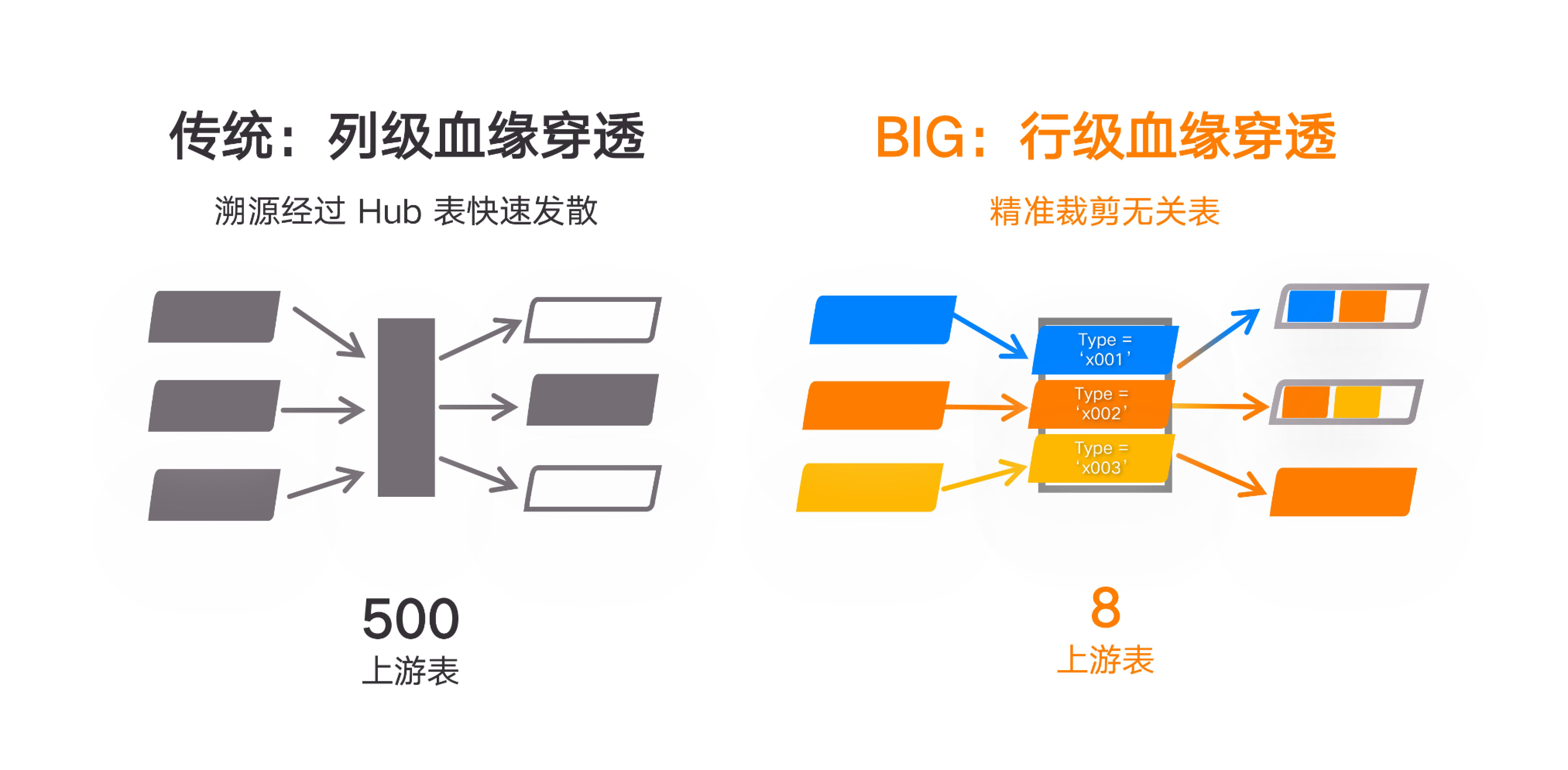
“精细”的另外一个表现在于其能够实现行级别的条件裁剪。在数仓建模过程中,IT 经常建立各种 Hub 型表或主题型表,比如将全域的线上、线下客户数据集中在一张全域客户表中,并通过类型字段进行区分,这类表在血缘分析过程中往往会带来灾难——一旦下游出现数据故障,想要向上游追溯时,数据血缘追溯会迅速扩散,导需要评估大量无关的上游数据。算子级血缘的核心突破在于它可以裁剪掉所有无关的上游,降低评估所需数据表的规模达几个数量级。这对于开展影响变更评估及异常根因定位的溯源工作能够带来巨大的效率提升。
Aloudata BIG 的算子级血缘的第二大显著优势是“准确”。首先,BIG 的解析能力对 SQL 写法没有约束,它支持几乎所有数据处理相关 SQL 语法(包括存储过程),现有的数据处理脚本无需改造,只要数据库能够执行,BIG 都能准确解析。其次,它不受任何函数限制或子查询的嵌套限制,并且能够穿透临时表。这使得 BIG 能够迅速解析出物理表间的依赖关系,并自动进行口径合并,从而清晰地展示整条数据链路。此外,BIG 的方言解析能力覆盖了市场上主流的数据仓库和计算平台产品,如 Hadoop、 GaussDB、PostgreSQL、Spark、Impala 等。为了确保解析的准确性,BIG 在出厂前会进行两套实现进行交叉比对,确保无误后才会发布。这种严谨的检验流程确保了解析结果的高准确度和可靠性。
Aloudata BIG 的算子级血缘解析能力的准确性还还表现为它能够理解非常复杂的任务脚本,覆盖了超过 99% 的任务编写场景。在任务脚本中,经常会包含多段 SQL 语句,而这些 SQL 之间往往存在着上下文关联。BIG 能够支持这些复杂情况的解析,包括:
全局任务变量、脚本内宏、脚本内变量、日期型变量的解析支持。
强大的流程控制解析能力。它能够精确解析临时表重复使用、变量重复赋值,以及 IF ELSE 分支等复杂情况。
动态 SQL 脚本支持,BIG 能够基于任务实例的日志进行精准的解析和补充。
这样极致的解析能力意味着 BIG 能够处理和理解极其复杂的数据处理逻辑,即使是建设达十年以上的数仓,也可以实现 99%以上的解析成功率。
Aloudata BIG 的算子级血缘解析能力的第三大显著优势体现在其“全面性”。这种全面性表现在 BIG 能够统一收集和解析整个数据链路的元数据,无论是位于数据链路起点的业务数据库,或是 ETL 工具,还是位于终端的 BI 工具,BIG 都能够全面连接、自动解析并清晰展现整个数据链路,确保从数据的来源到最终消费,每一个环节都能被精确捕捉和分析。这种全链路的解析能力对于任何依赖数据的企业而言都至关重要,它不仅提升了数据管理的透明度,还加强了对数据流动和使用的控制,从而为企业带来更高的数据管理效率和更强的决策支持能力。
企业数据管理的第二个主要难点是“管不住”,主要集中在以下几个方面:重点数据链路的可用性保障、重复资产的生产和治理,以及数据治理容易陷入治了又乱、乱了再治恶性循环的问题。
Aloudata BIG 主动元数据平台在算子级血缘能力的基础上,又实现了主动元数据管理,使得整个数据管理过程更加自动化,能轻松应对 EB 级别的大数据管理需求。
第一,在全链路可靠性保障方面,Aloudata BIG 的主动元数据管理功能主要包括全链路风险的主动感知、主动评估和主动告警。这些能力有助于在关键数据链路上节省大量管理成本和异常根因排查时间。平台能够利用其算子级血缘解析能力,准确地标记全链路数据,并主动收集全链路的元数据异常和变更事件。通过分析这些异常和变更事件及其对下游的影响,BIG 能够生成完整的链路风险报告,并主动通知所有与该变更或异常相关的下游用户。这种方法有助于快速感知异常和定位风险,从而提高数据管理的效率和准确性。
第二,Aloudata BIG 主动元数据管理能够实现精准的列级别口径判重,使得全域范围内的重复资产和数据烟囱现象无所遁形。在全域重复资产判重过程中,通常会面临重复资产定义标准难以统一和资产判重视野不全面的问题。凭借算子级血缘解析和对每个数据计算语义的精确理解,BIG 能够精准判断字段之间在计算语义上的不同级别差异。例如,判断它们是否来自同一数据源、是否采用相同的汇总方式、是否具有相同的汇总粒度或统计周期,甚至判断它们的数据范围是否一致。BIG 这种强大的判重能力已经在包含达 10 万级数据资产规模的生产环境中,实现了全域范围内的精准分级判重。这不仅有助于进行数据资产的盘点治理,还能大幅节省人力资源。通过这种方法,BIG 提供了一种高效的途径来优化数据管理和减少资源浪费。
第三,Aloudata BIG 让数据管理数据治理更加智能,其实现了模型治理的辅助驾驶(copilot),这使得模型治理的各个环节都能实现自动化,包括链路问题的识别、模型需求的盘点、模型代码的生成、新旧模型口径的比对,以及下游任务迁移代码的生成。借助算子级血缘和主动元数据,每个环节都可以自动化运行,极大地减少了人工工作量。
Aloudata BIG 的算子级血缘解析能力和主动元数据能力,在头部客户中已得到生产级验证。例如,某头部城商行面临数据血缘难以全面掌握、上游变更难以及时感知、异常根因定位耗时长的问题。使用 Aloudata BIG 后,该银行实现了监管报送和高管报表的全链路自动盘点和口径分析,且在 5 分钟内主动感知到数据链路的异常变更,并能在 30 分钟内快速定位异常根因。
在另一家头部股份制银行,其准备计划进行全域的数据仓库模型治理。面对庞大的数据资产规模,包括 2,000 万个字段和几十万个任务脚本,Aloudata BIG 的模型治理能力帮助客户在一周内就完成了全域数据模型盘点,并提出了 800 多份数据模型和链路优化建议,同时平均每天为客户生成近 200 份模型重构代码,极大提升了全域模型重构的效率。
Aloudata BIG 主动元数据平台是开启未来自动化数据管理的关键。通过算子级血缘解析,Aloudata BIG 精确描绘了全域数据资产的计算语义。又通过一系列算法实现了数据管理的自动化,无论是链路保障、主动的异常根因分析还是模型治理,其都为客户带来了显著的数据管理成本节约和效率提升。
近日,招商银行基于 Aloudata BIG 实现的“基于列算子血缘的模型优化和变更协同应用实践”,获评中国信通院 2023 大数据“星河”案例数据资产管理标杆案例。

目前,Aloudata BIG 主动元数据平台已在多个极高复杂度的数据环境中完成实地验证,欢迎点击进入官网,了解更多。

